Linux 系统调用内核源码分析
by FlyFlyPeng
什么是系统调用?
系统调用是应用程序与内核交互的一种方式。系统调用作为一种接口,通过系统调用,应用程序能够进入操作系统内核,从而使用内核提供的各种资源,比如操作硬件,开关中断,改变特权模式等等。首先,系统调用是一个软中断,既然是中断那么一般就具有中断号和中断处理程序两个属性,Linux 使用 0x80 号中断作为系统调用的入口,而中断处理程序的地址放在中断向量表里。
系统调用在内核空间和用户空间之间建立了一个连接的中间层,它主要为系统提供了下面三个主要功能:
- 第一,系统调用在底层硬件和用户空间之间建立了一个抽象的接口。例如,当用户空间的应用程序想读写一个文件时,程序员只需要通过系统调用接口完成读写操作即可,而不需要知道文件所在的底层磁盘是什么介质类型以及它所使用的是什么文件系统等一系列复杂的底层细节。
- 第二,系统调用让操作系统变得更加稳定和安全。Linux 中的内核好比就是一个仲裁者,它基于访问权限、用户组、临界区等机制来控制用户空间中应用程序用户空间中应用程序对底层硬件资源的访问,使得应用程序不会非法地使用硬件资源或者窃取其他应用程序所使用的资源以致对系统造成损害。
- 第三,系统调用便于实现系统虚拟化。系统调用提供的中间层,它屏蔽了许多的底层的细节,使得应用程序和底层系统的耦合性降低,这样系统的虚拟化变得更加简单。
系统调用的处理过程
当我们在用户态应用程序中调用一个系统调用函数时,它背后所隐藏的从用户态到内核态的整个处理过程,如下图所示:
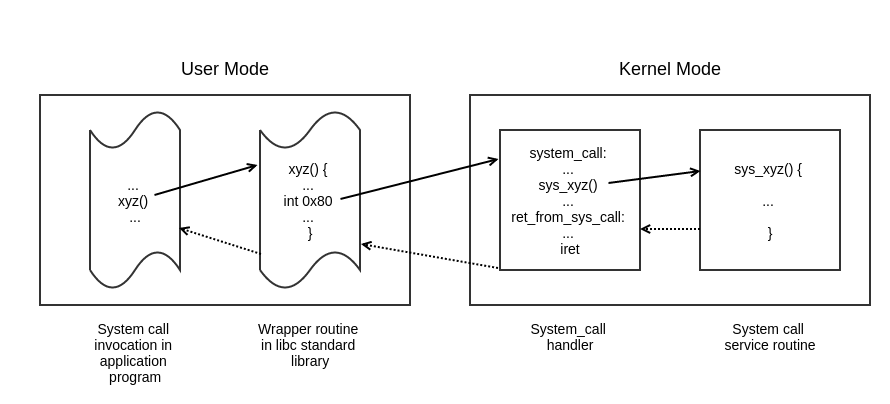
在上图中,应用程序中调用 libc 库中的封装好的 xyz() 系统调用函数,然后 xyz() 就接着执行 libc 库中 xyz() 函数的具体实现的代码,其中非常关键的一句代码就是 int 0x80,它使得进程从用户态切换到内核态,然后开始执行内核中系统调用处理程序的代码 system_call,在后面的分析中我们会看到这部分代码是用汇编语言编写的,接着在 system_call 系统调用处理程序就根据传入的系统调用号从系统调用服务程序数组中寻找对应系统调用服务程序,最后执行完成后按照调用顺序的相反顺序一步步返回结果。
在后面的系统调用内核代码分析中,我们将对其中所使用到的名称作一个规定说明:
- xyz():系统调用库函数
- system_call:系统调用处理程序
- sys_xyz(): 系统调用服务程序
系统调用例子
Linux 系统中实现了 300 多个系统调用,例如我们常用的 read、write、fork、time等等,有关 Linux 内核中定义了哪些系统调用,可以从 /arch/x86/syscalls/syscall_32.tbl中查阅到。
下面我们就介绍两种用户态下调用 sys_time 系统调用获取当前系统时间的方法。
使用 libc 中封装的好的 time 系统调用库函数
int Time(int argc, char *argv[])
{
time_t tt;
struct tm *t;
tt = time(NULL);
t = localtime(&tt);
printf("time:%d:%d:%d:%d:%d:%d\n", t->tm_year + 1900, t->tm_mon, t->tm_mday, t->tm_hour, t->tm_min, t->tm_sec);
return 0;
}
使用 Linux 内联汇编来直接调用 13 号系统调用 sys_time
int TimeAsm(int argc, char *argv[])
{
time_t tt;
struct tm *t;
asm volatile(
"mov $0,%%ebx\n\t"
"mov $0xd,%%eax\n\t"
"int $0x80\n\t"
"mov %%eax,%0\n\t"
: "=m" (tt)
);
t = localtime(&tt);
printf("time:%d:%d:%d:%d:%d:%d\n", t->tm_year + 1900, t->tm_mon, t->tm_mday, t->tm_hour, t->tm_min, t->tm_sec);
return 0;
}
系统调用内核代码分析
上面我们举的例子是在用户空间中调用系统调用函数,那么当从用户空间切换到内核空间中,内核是如何处理系统调用的呢?
系统调用处理程序初始化
首先,在内核启动初始化的 start_kernel 函数中就有一个对 trap 进行初始化工作的函数 trap_init() 函数,
/* 代码文件路径:/linux-3.18.6/init/main.c */
asmlinkage __visible void __init start_kernel(void)
{
......
trap_init();
......
}
而在 trap_init() 函数中就包含了对系统调用对应中断向量的初始化工作,它将系统调用对应的 0x80 号系统调用和它对应的处理程序关联起来,如下所示:
/* 代码文件路径:/linux-3.18.6/arch/x86/kernel/traps.c */
void __init trap_init(void)
{
......
#ifdef CONFIG_X86_32
set_system_trap_gate(SYSCALL_VECTOR, &system_call);
set_bit(SYSCALL_VECTOR, used_vectors);
#endif
......
}
上面第 6 行代码中的 SYSCALL_VECTOR 的定义如下所示:
/* 代码文件路径:/linux-3.18.6/arch/x86/include/asm/irq_vectors.h */
......
#ifdef CONFIG_X86_32
# define SYSCALL_VECTOR 0x80
#endif
......
我们可以看到 SYSCALL_VECTOR 对应的中断向量号就是我们上面使用内联汇编例子中 int 0x80 指令中的中断向量号。
而 0x80 中断向量对应中断向量的中断服务程序就是上面 set_system_trap_gate() 函数中所设置的 system_call 程序,它是处理系统调用的入口程序。
系统调用处理程序分析
当执行 int 0x80 之后,系统就从用户态切换到内核态,并跳转到了 0x80 中断向量号 对应的中断向量服务程序 system_call,该服务程序的代码位置是:/linux-3.18.6/arch/x86/kernel/entry_32.S 文件中的 490 行处的 ENTRY(system_call)。由于这部分的汇编代码涉及到比较多的知识,所以下面的代码是作了一些精简,保留了最核心的那部分代码:
/* 代码文件路径:/linux-3.18.6/arch/x86/kernel/entry_32.S */
# system call handler stub
# 系统调用汇编代码的起点
ENTRY(system_call)
# step 1:
SAVE_ALL # 进入中断处理程序前,保存内核态下的现场
......
cmpl $(NR_syscalls), %eax # 比较传入的系统调用号是否大于最大的系统调用号
jae syscall_badsys # 如果传入的系统调用号太大,则跳转到处理无效系统调用号的处理程序
# step 2:
syscall_call:
call *sys_call_table(,%eax,4) # 根据 eax 中传入的系统调用号来调用对应的系统调用服务程序,在我们的例子中就是调用 sys_time
# step 3:
syscall_after_call:
movl %eax,PT_EAX(%esp) # store the return value, 保存系统调用后返回的值到 eax 中
# step 4:
syscall_exit: # 会检测要不要执行syscall_exit_work,正常情况会有一些需要处理的工作,比如当前进程有一些信号要处理,系统需要进行调度
......
movl TI_flags(%ebp), %ecx
testl $_TIF_ALLWORK_MASK, %ecx # current->work
jne syscall_exit_work
# step 5:
restore_all:
restore_nocheck:
RESTORE_REGS 4 # skip orig_eax/error_code
irq_return:
INTERRUPT_RETURN # 这是一个宏定义,本质上是一条 iret 指令
# system_call 结束位置
......
ENDPROC(system_call)
由于代码比较长,所以我们在上面的代码中加入了 “step n” 的注释,将代码分成 5 个步骤进行解析。首先,通过一个流程图对内核源码中系统调用的处理过程进行一个概要性地描述。
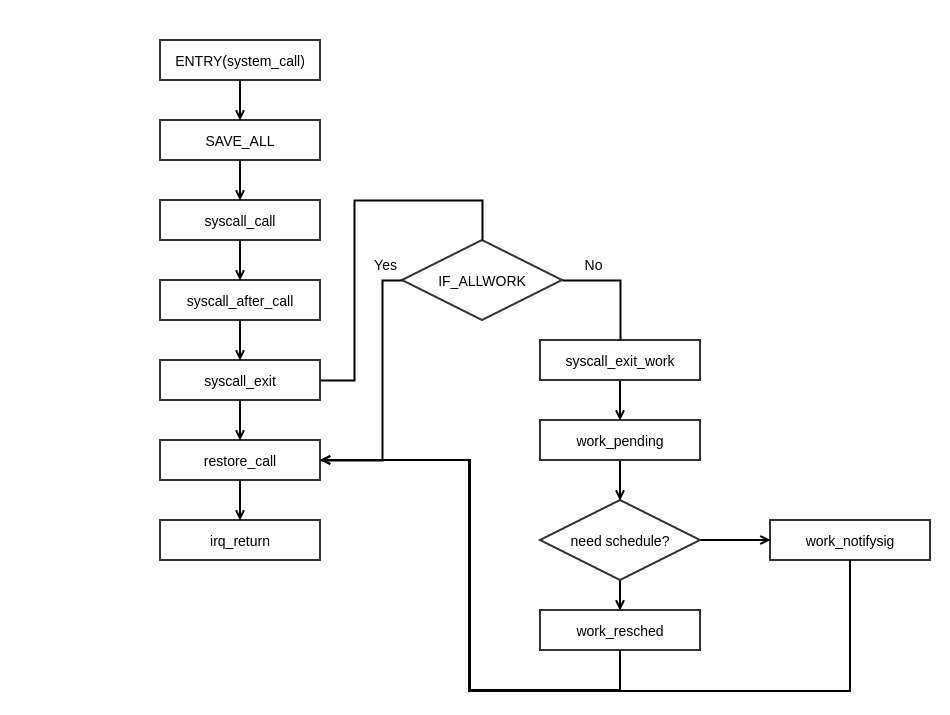
step 1
内核源码是从 Entry(system_call) 入口处开始处理系统调用,然后通过 SAVE_ALL 宏来保存一下当前的上下文状态,SAVE_ALL 宏的具体代码实现如下所示:
/* 代码文件路径:/linux-3.18.6/arch/x86/kernel/entry_32.S */
# 在进入中断处理程序前,保存相关寄存器的值
.macro SAVE_ALL
cld
PUSH_GS
pushl_cfi %fs
/*CFI_REL_OFFSET fs, 0;*/
pushl_cfi %es
/*CFI_REL_OFFSET es, 0;*/
pushl_cfi %ds
/*CFI_REL_OFFSET ds, 0;*/
pushl_cfi %eax
CFI_REL_OFFSET eax, 0
pushl_cfi %ebp
CFI_REL_OFFSET ebp, 0
pushl_cfi %edi
CFI_REL_OFFSET edi, 0
pushl_cfi %esi
CFI_REL_OFFSET esi, 0
pushl_cfi %edx
CFI_REL_OFFSET edx, 0
pushl_cfi %ecx
CFI_REL_OFFSET ecx, 0
pushl_cfi %ebx
CFI_REL_OFFSET ebx, 0
movl $(__USER_DS), %edx
movl %edx, %ds
movl %edx, %es
movl $(__KERNEL_PERCPU), %edx
movl %edx, %fs
SET_KERNEL_GS %edx
.endm
从上面 SAVE_ALL 的实现代码中,我们可以知道 SAVE_ALL 的主要工作就是将 gs、fs、es、ds、eax、ebp 等寄存器中的值在调用系统调用服务程序之前将其压入到内核栈中保存。
接下来的 cmpl 指令语句则是用来判断从用户态传入的系统调用号是否大于系统中所实现的最大的系统调用编号,如果是,那么就说明我们传入的系统调用编号不合法,程序就跳转到 syscall_badsys 处执行相应的出错处理程序。
step 2
在 step 2 中的工作就是就是去调用与传入系统调用号对应的系统调用服务程序,而这一步中就只有一条非常简单的 call 指令语句,如下所示:
call *sys_call_table(,%eax,4) # 根据 eax 中传入的系统调用号来调用对应的系统调用服务程序,在我们的例子中就是调用 sys_time
那么程序是怎么通过 %eax 中保存的系统调用号返回指定的系统调用服务程序的起始地址的呢?
我们首先可以从 sys_call_table 入手分析!
sys_call_table 代码:
/* 代码文件路径:/linux-3.18.6/arch/x86/kernel/syscall_32.c */
#define __SYSCALL_I386(nr, sym, compat) [nr] = sym,
typedef asmlinkage void (*sys_call_ptr_t)(void);
extern asmlinkage void sys_ni_syscall(void);
__visible const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_32.h>
};
从上面的代码中,我们可知 sys_call_table 是一个数据元素为函数指针类型的的数组,数组长度就是系统中所包含的全部系统调用的数量: __NR_syscall_max + 1,然后在这个花括号里面的代码完成的就是对数组元素初始化的工作。
也许你会对 [0…__NR_syscall_max] 这样风格的代码感到陌生和疑惑,其实它的功能就是将数组中从 0 号数组元素到 __NR_syscall_max 数组元素全部初始化成 &sys_ni_syscall(sys_ni_syscall 是系统中未实现的系统调用的默认系统调用服务程序),有关这个数组初始化的方式,更多详细的内容请参考下面这篇博客 Linux Kernel代码艺术——数组初始化。
在默认的系统调用服务程序之后,就是每个已经在系统中有对应实现的系统调用的初始化,但是在这里只有一个 include 语句啊?我们还是首先来看看 include 的 asm/syscall_32.h 中内容是什么:
/* 代码文件路径:/linux-3.18.6/arch/x86/include/asm/syscalls_32.h */
__SYSCALL_I386(0, sys_restart_syscall, sys_restart_syscall)
__SYSCALL_I386(1, sys_exit, sys_exit)
__SYSCALL_I386(2, sys_fork, stub32_fork)
__SYSCALL_I386(3, sys_read, sys_read)
__SYSCALL_I386(4, sys_write, sys_write)
__SYSCALL_I386(5, sys_open, compat_sys_open)
__SYSCALL_I386(6, sys_close, sys_close)
__SYSCALL_I386(7, sys_waitpid, sys32_waitpid)
__SYSCALL_I386(8, sys_creat, sys_creat)
__SYSCALL_I386(9, sys_link, sys_link)
__SYSCALL_I386(10, sys_unlink, sys_unlink)
__SYSCALL_I386(11, sys_execve, stub32_execve)
__SYSCALL_I386(12, sys_chdir, sys_chdir)
__SYSCALL_I386(13, sys_time, compat_sys_time)
......
在这个文件中全部都是 __SYSCALL_I386 对应的宏代码,而 __SYSCALL_I386 宏的定义就在前面的 syscall_32.c 文件中,
#define __SYSCALL_I386(nr, sym, compat) [nr] = sym,
所以,展开一下 __SYSCALL_I386(1, sys_exit, sys_exit) 这样一条宏语句,它本质上就是等价于:
[1] = sys_exit
总结一下,也就是说 sys_call_table 数组是一个存储系统调用服务程序的这么一个数组,例如系统中 0 号元素保存的是 0 号系统调用服务程序的地址,1 号元素保存的是 1 号系统调用的处理函数地址,如果某个系统调用没有对应的服务程序,那么对应数组元素保存的就是用默认的系统调用服务程序 sys_ni_syscall 地址。
因此,call *sys_call_table(,%eax,4) 含义就是根据寄存器 %eax 中系统调用号,跳转到对应的系统调用服务程序中去执行。在分析这条语句时,我卡壳了半天一直不知道 sys_call_table 后面括号中的参数是什么含义,后面 google 了以后才想起来这是 AT&T 汇编中的间接寻址方式,也就是说对应的系统调用处理函数的地址在是在 *(sys_call_table + %eax * 4) 的位置处,这里有个 4 表示的含义是数组中每个元素大小是 4 字节。
接下去,通过 call 指令程序就会跳转到对应的系统调用服务程序中去执行具体的操作,最后将执行后的结果保存到 eax 寄存器中后返回。
step 3
step 3 中的代码就比较简单了,它就是将系统调用处理函数返回的状态值保存在 eax 寄存器中的结果保存到内核栈中,保存的位置就是在 SAVE_ALL 宏中保存 eax 寄存器值的位置。
在这里补充一点的就是,系统调用服务程序执行完成之后保存在 eax 寄存器中返回值就是一个整型数据,用来表示系统调用成功与否!一般来说,返回的值是负数则表示此次系统调用失败,而返回值为 0 则表示此次系统调用成功,具体系统调用失败的原因,我们可以在应用程序中通过 perror() 函数来输出相应的出错信息。
step 4
step 4 中首先读取 thread_info 结构体中的标志位,如果在发生系统调用的同时当前进程还接收到一些信号,那么程序就会接着跳转到 syscall_exit_work 处去执行有关信号处理相关的相关的代码,以及此时可能系统还会进行一个进程调度的工作,最后处理完这些系统调用返回前的操作之后,系统调用处理程序就接着往下执行到 step 5。
syscall_exit_work 的代码如下所示:
/* 代码文件路径:/linux-3.18.6/arch/x86/kernel/entry_32.S */
syscall_exit_work: # 退出系统调用后所做的一些工作
testl $_TIF_WORK_SYSCALL_EXIT, %ecx
jz work_pending # 跳转到 work_pending 去处理一些信号相关的处理程序
TRACE_IRQS_ON
ENABLE_INTERRUPTS(CLBR_ANY) # could let syscall_trace_leave() call
# schedule() instead
movl %esp, %eax
call syscall_trace_leave
jmp resume_userspace
END(syscall_exit_work)
step 5
完成系统调用服务程序的一系列处理之后,最后所需要做的工作就是返回到系统调用处理程序中,恢复调用系统调用服务程序前的内核的上下文状态,也就是将保存在内核栈中的寄存器的值恢复到相应的寄存器中,而这一步主要是由 RESTORE_REGS 宏来完成,它的定义如下所示:
/* 代码文件路径:/linux-3.18.6/arch/x86/kernel/entry_32.S */
# 执行完中断处理程序后,返回时恢复原来保存在栈中的寄存器的值
.macro RESTORE_INT_REGS
popl_cfi %ebx
CFI_RESTORE ebx
popl_cfi %ecx
CFI_RESTORE ecx
popl_cfi %edx
CFI_RESTORE edx
popl_cfi %esi
CFI_RESTORE esi
popl_cfi %edi
CFI_RESTORE edi
popl_cfi %ebp
CFI_RESTORE ebp
popl_cfi %eax
CFI_RESTORE eax
.endm
.macro RESTORE_REGS pop=0
RESTORE_INT_REGS
1: popl_cfi %ds
/*CFI_RESTORE ds;*/
2: popl_cfi %es
/*CFI_RESTORE es;*/
3: popl_cfi %fs
/*CFI_RESTORE fs;*/
POP_GS \pop
.pushsection .fixup, "ax"
4: movl $0, (%esp)
jmp 1b
5: movl $0, (%esp)
jmp 2b
6: movl $0, (%esp)
jmp 3b
.popsection
_ASM_EXTABLE(1b,4b)
_ASM_EXTABLE(2b,5b)
_ASM_EXTABLE(3b,6b)
POP_GS_EX
.endm
我们可以从上面的代码中看到 RESTORE_INT_REGS 宏从栈中恢复寄存器的值顺序刚好是和前面所提到的 SAVE_ALL 宏压栈的顺序是相反的。
恢复了内核态中内核栈的状态之后,接下来就是执行 INTERRUPT_RETURN 宏了,而这个宏实际上就是 iret 指令,它将系统从内核态又切换回用户态,然后使得用户态的应用程序往下接着执行。
系统调用服务程序分析
应用程序调用某个系统调用的目的就是完成一些无法在用户空间完成的操作,从而得到想要的结果。我们前面大费周章讲到的系统调用处理程序就像是一个领路者,它把应用程序想要内核代替执行的操作,从用户空间传递到内核空间,然后再从内核空间中找到对应的服务程序去处理它。
因此,我们在这个小节中所要分析就是系统调用程序在内核中是如何实现的?我们还是以前面的 13 号系统调用 time 为例。
在前面一节系统调用处理程序分析中的 step 2 中,我们知道系统调用号和系统调用服务程序是一一对应关系,一个系统调用对应一个系统调用服务程序。而我们所要分析的 13 号系统调用对应的系统调用服务程序就是 sys_time,如下所示:
/* 代码文件路径:/linux-3.18.6/arch/x86/include/asm/syscalls_32.h */
__SYSCALL_I386(13, sys_time, compat_sys_time)
那么,sys_time() 函数是怎么实现的呢?
sys_time() 函数的代码实现如下所示:
/* 代码文件路径:/linux-3.18.6/kernel/time/time.c */
SYSCALL_DEFINE1(time, time_t __user *, tloc)
{
time_t i = get_seconds();
if (tloc) {
if (put_user(i,tloc))
return -EFAULT;
}
force_successful_syscall_return();
return i;
}
为什么不是 sys_time() 作为函数名呢?其实规范统一的系统调用服务程序接口, Linux 系统中的系统调用服务函数都是使用 SYSCALL_DEFINEx (x可以0,1,2,3…等数字)宏来实现的。
SYSCALL_DEFINEx 的定义如下所示,
/* 代码文件路径:/linux-3.18.6/include/linux/syscalls.h */
#define SYSCALL_METADATA(sname, nb, ...)
#endif
#define SYSCALL_DEFINE0(sname) \
SYSCALL_METADATA(_##sname, 0); \
asmlinkage long sys_##sname(void)
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(SyS##name)))); \
所以根据上面的定义,宏 SYSCALL_DEFINE1(time, time_t __user *, tloc) 展开后得到的结果就是:
asmlinkage long sys_time(time_t __user *tloc);
参考文章
Subscribe via RSS