CPU 是如何工作的?
by FlyFlyPeng
CPU 发展历史
20 世纪 70 年代微处理器(microprocessor)的发展,深刻地影响了 CPU 的设计与实现。Intel 最早在 1971 年推出了它的第一款微处理器,也是全球第一款微处理器:Intel 4004;而到了 1974 年,Intel 又是第一个推出了全球第一款称得上处理器的芯片:Intel 8080 ,这款处理器芯片一经推出后就得到了各大计算机厂商的青睐,因为它采用了全新的制造工艺,完全取代了其他微处理器的原有的制作工艺,它将 CPU 变地更小更快,并且随着这款芯片的广泛应用, Intel 慢慢地也形成了自己独有的指令集。
伴随着 CPU 的快速发展以及个人电脑的不断普及,CPU 一词也逐渐地取代了微处理器(microprocessor),用来表示计算中最核心的功能部件。
早期 CPU 它主要是由多个分离的功能部件和许多微小的集成电路集成在一个电路板上。随着 CPU 制作工艺的快速发展,现在 CPU 的制作工艺已经达到了 20 nm 的级别,同时 CPU 的主频也从原来的百兆级(MHz)别发展到现在千兆级别(GHz)。此外,集成电路的迅猛发展使得在单个 CPU 中的晶体管的数量及复杂性也显著地增加,这也让 CPU 变得越来越快。后来这种 CPU 的发展趋势就就被描述成摩尔定律(Moore’s law)其内容为:
集成电路上可容纳的电晶体(晶体管)数目,约每隔24个月便会增加一倍;
尽管 CPU 的尺寸、制作工艺不断地在发展变化,但是我们现在几乎所有正在使用的 CPU 还都是基于冯诺依曼的存储程序的计算机模型设计的。
摩尔定律的预测到现在为止还依然非常准确,但是由于集成电路晶体管技术在往更微小的级别发展时受到了限制,摩尔定律的极限也逐渐在逼近。尤其当晶体管的栅极长度足够短的时候,量子隧穿效应就会发生,会导致漏电流增加。正是由于上面这些新的问题的产生,使得有越来越多的研究学者投入到新的计算机模型的研究上,例如量子计算机。与此同时,还有许多研究人员基于传统的冯诺依曼的计算机模型不断地扩展计算机的并行处理能力,达到加快计算机运行的目的。
什么是 CPU?
CPU 是计算机的大脑,是计算机中最重要的部件,通常也被称为中央处理单元。CPU 最核心的功能就是读取和执行指令。而整个 CPU 主要由以下几个部件组成:
- 算术逻辑运算单元(ALU)
- 控制单元
- 寄存器
- 总线
下图是一个 CPU 内部结构的简图:
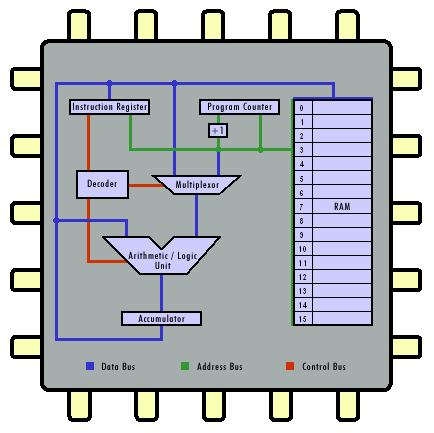
CPU 的组成
算术逻辑运算单元(ALU)
ALU 它本质上是一个数字电路,它的主要功能就是输入的数据进行算术运算操作(例如,加法-add,减法-sub)和逻辑运算操作(例如,与-&,异或-^),因此它也是 CPU 中最最基础的功能部件。
控制单元
控制单元控制着 CPU 内部的指令流和数据流的流动。控制单元本质上也是由多个数字电路模块组成,例如上图中出现的多路选择器、指令译码器。
寄存器
寄存器是 CPU 中特殊的存储区域,CPU 能够快速地从其中访问到其中的数据,它是计算中最快的存储器,但数量也非常有限。在 CPU 中的寄存器可以简单地分为下面几类:
- 指令寄存器(Instruction Register,IR):用来保存当前正在执行的一条指令。
- 程序计数器(Program Counter,PC):用来指出下一条指令在主存储器中的地址。
- 通用寄存器:用于传送和暂存数据,也可参与算术逻辑运算,并保存运算结果。例如,16 位 cpu 通用寄存器共有 8 个:AX,BX,CX,DX,BP,SP,SI,DI.
- 累加寄存器(Accumulator,AC):它是一个通用寄存器,例如在 Intel 8086 16 位处理器中累加寄存器通常是由通用寄存器组中的 AX 来充当。它的主要功能就是当运算器的算术逻辑单元 ALU 执行算术或逻辑运算时,可以为 ALU 暂时保存一个操作数或运算结果。
- 程序状态字寄存器(Program Status Word,PSW):用来表征当前运算的状态及程序的工作方式。
总线
总线是 CPU 中连接上述各个部件的高速传输通道,它能够在各个部件之间高速地传输数据。而 CPU 内部的总线可以分为下面 3 种:
- 数据总线
- 控制总线
- 地址总线
CPU 是怎么工作的?
传统的基于冯诺依曼体系结构的 CPU,它采用的存储程序的模型来实现的,简单地说它就是首先将程序存储在主存当中,然后 CPU 不断的进行 “fetch-decode-execute” 的这样一个指令处理过程。CPU 的一个指令周期中所执行的操作可以分为下面 4 个阶段:
- fetch:获取指令
- decode:指令译码
- execute:执行指令
- writeback:数据结果写回
整个指令的过程,如下图所示:
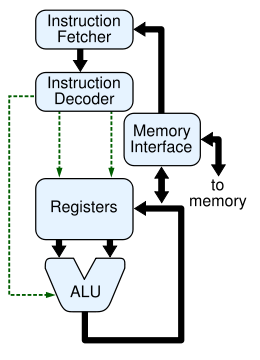
fetch:获取指令
CPU 在一个指令周期第一步需要做的就是获取指令。CPU 会从内存当中存储程序指令的地址开始取出指令(指令在内存中也是通过数字进行表示的,它由操作码和数字共同组成)。那么我们不经要想 CPU 怎么知道程序指令的存放地址呢?其实在 CPU 的内部还有一个叫做程序计数器的寄存器(PC),它存储了当前指令在内存中的存储地址,并且每当 CPU 取出一条指令后,PC 寄存器中的值就被修改为程序中下一条执行指令的地址。如果 CPU 每次都从内存中进行取指令,由于 CPU 的执行速度远远快于内存的访问速度,所以就会导致 CPU 会出现等待的情况,降低了 CPU 的利用率。为了解决上面这种问题,在现代的 CPU 处理器中引入了 Cache 缓存和流水线技术。
decode:指令译码
CPU 从内存中取出了指令,而这个指令的目的就是告诉 CPU 接下来该做什么操作。在指令译码阶段,每条指令会被分割成操作码和操作数两部分,其结构如下所示:
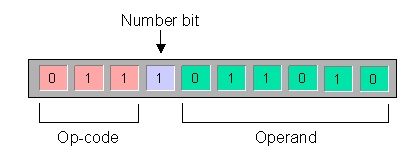
CPU 中每条指令所代表的具体含义是由处理器对应的指令集(ISA)进行解析。指令当中的操作码部分表示的含义是该指令将会执行什么样的操作,而剩余的部分则表示指令执行某种操作时所需要的操作数,例如在 add 指令中,指令操作码后面的数据表示的就是加法操作所需要的两个操作数的相关信息。而在指令中的操作数,它可以是一个常数(也叫立即数),也可以是一个保存有操作数据的寄存器,还可以是一个操作数在内存中的地址,这主要取决于指令中操作数的寻址方式。
execute:执行指令
完成了上面的指令译码操作之后,CPU 就进入了执行指令的阶段。在这个阶段中 CPU 中的各个部件会协同工作来完成指令中操作码所指定的操作。例如,CPU 正在执行一条 add 指令,那么算术逻辑单元(ALU)就会被使用到,并且 ALU 会和一组存放 输入数据的寄存器和存放最终运算结果的输出数据关联在一起。如果最终 add 指令产生的输出值太大,以致于 CPU 无法处理,那么 CPU 中的程序状态字寄存器(PSW)中的算术溢出(arithmetic overflow)标志就会被置位。
writeback:数据结果写回
最后一步,数据结果写回(writeback),也就是说将通过指令执行得到的数据结果写回到以某种形式存在的存储空间中。通常,指令执行得到的数据结果都是写回到 CPU 中的寄存器组中,这主要是根据时间局部性的原理:接下来执行的指令很可能需要访问上一条指令得到的数据结果。因此,如果将上一条指令执行得到的数据结果保存在寄存器中,CPU 可以非常快速地访问到它。而在另外一些场合中,我们有时需要将执行执行的结果数据写回到价格更加便宜,存储空间更大的内存当中。
这里还有一点需要特别注意的就是,CPU 指令集中还存在一些指令,它执行之后不会产生新的数据结果,而只是修改了 PC 寄存器的值,这类指令我们通常称它是跳转指令(Jump)。通常程序中的循环、条件判断以及函数调用,在编译成机器指令时就会使用到跳转指令来决定程序的执行路径。
CPU 中还有一些指令,它们在执行之后除了得到对应的数据结果之外,同时还会影响到 PSW 寄存器中相应标志位的值。举个例子,一条 cmp 指令它所执行的是比较输入的两个数的大小关系,然后指令执行完成之后,它会根据两个数据的大小关系来设置 PSW 中相应标志位。然后,接下来的执行的跳转指令可能就会根据这个标志位来决定程序接下来跳转到哪个位置接着往下执行。
指令重复执行
在完成上面的指令执行阶段和数据结果写回操作之后,一个 CPU 的指令周期就此结束了,紧接着 CPU 又根据 PC 寄存器中的值来取出下一条指令,同样还是进行 “fetch-decode-execute-writeback” 的处理过程,然后指令一条接一条地重复上面的过程。如果使用的是更加高级和更加复杂的 CPU 的话,在一个指令周期中,还可以同时进行指令的 “fetch-decode-execute-writeback” 的处理过程。所以说,CPU 其实还是挺笨的,它只会做一些重复性的工作,而不会像人类一样进行思考。
总结
通过上面的简单介绍,其实你会发现 CPU 的基本工作原理还是非常简单易懂的,只要你能搞清楚它内部的组成结构以及它在一个指令周期中进行什么样的操作。虽然现在的 CPU 在性能、设计、制作工艺已经远远超过了最开始的 Intel 8080 处理器,但是万变不离其宗,它们现在还是使用者相同的数学模型,那就是冯诺依曼的存储程序计算机模型,所以说它们的基本原理在本质上没有发生太大的变化。
如果你想进一步深入地了解有关 CPU 的当前发展情况,那么你可以去看下 《计算机体系结构:量化研究方法》 这本书,从这本书中你可以了解到高级流水线、指令多发射、Cache 一致性等更加高级的 CPU 相关的问题。
参考文章
Subscribe via RSS