论文分享 - VirtualFlow: Decoupling Deep Learning Models from the underlying Hardware
by FlyFlyPeng
Reference
Or, Andrew, Haoyu Zhang, and Michael None Freedman. “Virtualflow: Decoupling deep learning models from the underlying hardware.” Proceedings of Machine Learning and Systems 4 (2022): 126-140.
FAQ
- Tensorflow的AI框架中已经用Executor的概念抽象解耦了底层的实际执行硬件,VirtualFlow所抽象的Virtual Nodes与Executor相比有什么差异?
传统的AI框架中Virtual Nodes和Physical Accelerators资源的映射关系是
1:1,例如在Tensorflow中每个GPU设备对应一个抽象的Executor对象。 但是这只是时间和资源空间中的一种划分方式 VirtualFlow则是将时间和资源两个维度组成的空间进行划分,拓展了传统AI框架中的Virtual Nodes和Physical Accelerators资源1:1的映射关系 VirtualFlow的一个创新点就在于用时间换空间,并保持模型的收敛速度和模型精度不变 - 模型的收敛性和batch-size/learning-rate这些的hyperparameters之间的关系是什么?
在说模型收敛的时候,一般指的是训练、验证损失曲线没有大的波动,而且随着训练轮数不断增加,波动依然可以在一定容忍范围内。 个人理解,收敛的意义是系统稳定,就是模型的某一个权重参数发生小的改变的时候,模型输出结果不会发生强烈变化,导致系统崩溃,也就是所谓的发散。 网络模型不收敛直观体现是loss函数无法下降,本质上是网络或者训练方法有问题,包括batch-size大小,是否数据归一化,学习率设计,初始化权重等,这些都需要检查一下1
- VirtualFlow的Virtual Nodes是怎么保证模型的收敛性?
场景说明:原来大模型难以在资源较小规模的GPU集群上直接复用原来的Hyperparameters进行训练,因为原来在大集群上使用的batch-size在不修改的情况下,在小规模的GPU集群上运行不起来。如果直接调整模型的Hyperparameters适应小规模的GPU集群,那么就会存在模型收敛性和模型精度变化的问题 所以,VirtualFlow是直接用与原始大规模集群训练场景相同数量的Virtual Nodes节点来模拟原始大规模集群中的GPU节点,这样就不需要调整模型的Hyperparameters参数。 文中的一个可重现相同模型精度的实验设计,也可以看到所有的实验对照组中所有的virtual nodes的数量是相同。
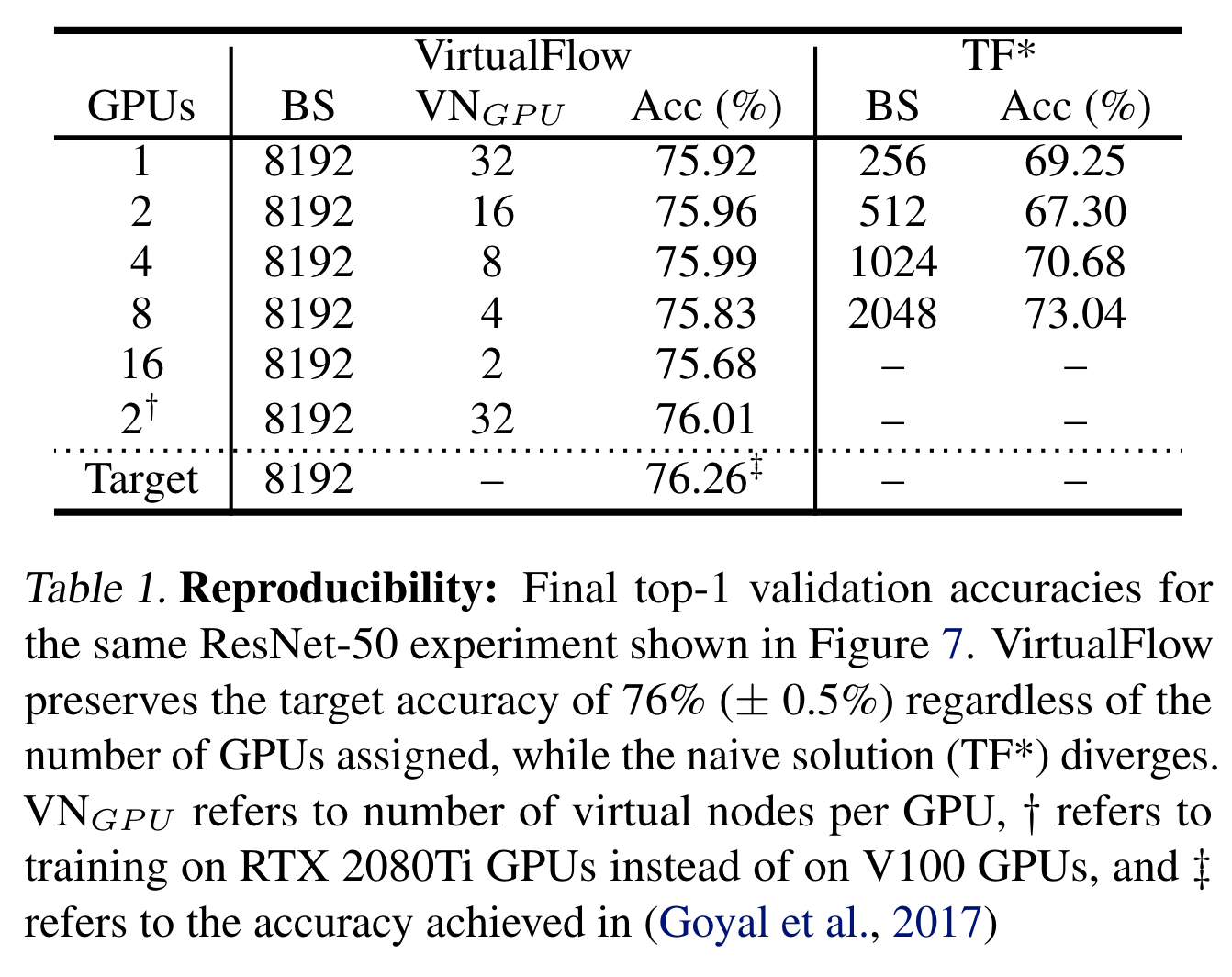 总结一下就是VirtualFlow通过Virtual Nodes模拟出了和原场景相同的GPU数量,自己封装了Virtual Nodes到Physical GPU Resource之间的复杂的映射关系和处理逻辑
总结一下就是VirtualFlow通过Virtual Nodes模拟出了和原场景相同的GPU数量,自己封装了Virtual Nodes到Physical GPU Resource之间的复杂的映射关系和处理逻辑 - VirtualFlow中不同模型的Virtual Nodes设置多大才比较合适呢?
这个需要根据具体的场景进行选择。
- 在论文中重点提到的用小规模GPU集群模拟大集群分布式的训练场景下,Virtual Nodes的数量应该和原始场景中GPU的数量保持一致
- 如果是利用VirtualFlow实现利用不同类型GPU资源的异构训练场景时,则需要通过论文中提到的异构资源分配求解器 + 离线特征提取进行求解,得到最优地资源分配方式
背景
模型与底层硬件强耦合的两个因素:
- Hyperparameters与底层硬件强耦合
- 训练过程中的Hyperparameters(例如learning rata, batch size, dropout rate)对于模型收敛性影响非常大
- 一些利用大规模加速器硬件资源和大batch-size训练得到的模型,很难通过小规模的加速器资源复现出相同的模型结果,主要原因是大规模训练集群中batch-size较大,而相同的batch-size无法适用在小规模的集群中,如果通过缩小batch-size大小,则模型训练的收敛性则存在较大的差异
- 模型的计算图与底层硬件强耦合
- 计算图中会强耦合底层硬件加速器资源的信息(例如分布式训练中的模型参数同步策略)
- 模型训练过程中资源弹性扩展性差,调整硬件加速器资源需要涉及到一系列的模型参数checkpoint和restore,计算图重新编译优化等一系列操作
Virtual Node处理流程
Virtual Node概念抽象:
- 从模型的角度来看,计算单元就是虚拟的Virtual Nodes,只要Virtual Nodes的数量不发生变化,那么模型的batch-size和收敛精度都将保持不变

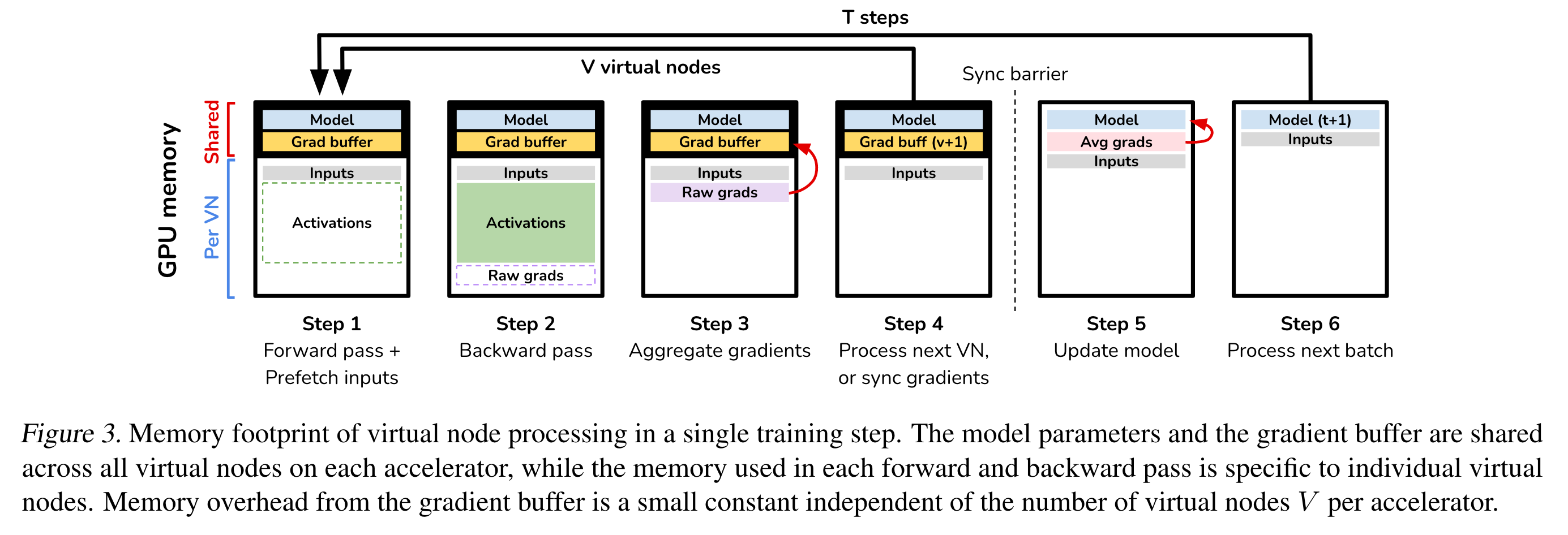
VirtualFlow内存开销
- VirtualFlow的内存开销主要来自于Gradient Buffer,这个Buffer是同一个物理硬件加速器的所有Virtual Node所共享
- Gradient Buffer的大小跟模型参数大小成正相关,与batch-size无关,通常在训练过程中只占显存非常小的一个比例
VirtualFlow中关于时间和资源的权衡:
- 传统的AI框架中Virtual Nodes和Physical Accelerators资源的映射关系是
1:1,但是这只是时间和资源空间中的一种划分方式 - VirtualFlow则是将时间和资源两个维度组成的空间进行划分,拓展了传统AI框架中的Virtual Nodes和Physical Accelerators资源
1:1的映射关系 - VirtualFlow的一个创新点就在于用时间换空间,并保持模型的收敛速度和模型精度不变

资源弹性扩缩容
VirtualFlow相比于已有的GPU Cluster Schedulers的区别:
- 在集群底层物理加速器资源扩缩时,无需中断已经在运行的Job和从checkpoint处恢复执行
- 已有的GPU集群调度器无法在不损害模型收敛性和精度的条件下,动态地重新调整模型训练任务所需的资源大小(举了一个例子,Job A需要2个GPU,Job B需要8个GPU,但是现在环境上只有8个GPU,如果无法调整Job的资源需求大小,那么这两个Job根本无法同时运行,而当Job A运行时,则剩余的6个GPU就会浪费)
能够动态地调整Job对于资源的需求,可以大大地增加新的调度机会点
多种异构资源协同训练
当前最新的AI框架在加速器资源分配时有一个前提假设:同一个Job只能分配使用相同的加速器资源(同种架构和同种硬件型号)
存在的两个挑战:
- 如何有效地将virtual nodes映射到实际的异构加速器资源?
- 离线特征提取:根据不同type resource类型和batch-size进行进行offline profiling,获取到不同type resource各自batch-size和throughput之间的关系
- 异构资源分配求解器:通过公式归一化抽象出得到异构资源的分配方式,然后进行求解
- 如何提供与同构资源相同的训练语义?
- 梯度值同步:通过不同的加速器上的梯度加权平均方法,保证梯度同步时的不同加速器设备上的梯度值汇聚均分时的正确性
- 数据分片

实验分析
直接看论文里面的Evaluation章节吧,实验部分主要分为:
- 验证大规模集群模型训练在小规模集群上的复现,并保持模型精度不下降
- 验证VirtualFlow框架的资源弹性伸缩能力
- 验证VirtualFlow框架的多类型异构资源协同训练能力
总结
- VirtualFlow的核心思想类似于GPU虚拟化中的一虚多,同一个物理GPU分时模拟多个GPU,它的一个好处就是不需要等到所有的物理资源需求都满足时才能开始工作,可以更灵活地组合多个任务共同执行,提高整个资源的资源利用率
- VirtualFlow的主要工作
- 模型收敛性保障:小规模GPU集群模拟大规模集群训练模型的场景,可以保证模型的收敛性和模型精度
- 资源弹性伸缩:VirtualFlow维护了Virtual Node到Physical GPU之间的映射关系,可以动态地调整物理资源在各个Job之间分配,提高资源利用率,并屏蔽底层物理资源动态伸缩带来的影响
- 异构资源协同训练:充分利用系统中多种异构计算资源,通过Virtual Nodes屏蔽底层资源的差异,利用离线训练提取关键特征,然后通过求解器得出最优地Virtual Node到Physical Node的映射关系
- 论文中没有详细地阐述关于Virtual Node是如何建模的,例如它模拟的GPU的显存多大,CUDA Core的数量是多少。如果Virtual Node模拟的显存大于底层实际GPU硬件设备的显存大小,Virtual Node就无法完成到实际GPU设备之间的映射
- VirtualFlow在大模型场景(单个模型参数大小无法存放在单个GPU节点上)时,如何将模型并行和数据并行相结合;还有复杂的多节点分布式训练场景下,如何做好Virtual Node到Distributed Physical GPU资源之间的映射(好像这种情况就退化成了GPU资源池化拉远的场景)
参考资料
Subscribe via RSS