Python 学习笔记(1)
by FlyFlyPeng
![]()
1. Python简介
Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言[1]。
Python就为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。
除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。
总的来说,Python的哲学就是简单优雅,尽量写容易看明白的代码,尽量写少的代码。如果一个资深程序员向你炫耀他写的晦涩难懂、动不动就几万行的代码,你可以尽情地嘲笑他。
那Python适合开发哪些类型的应用呢? 首选是网络应用,包括网站、后台服务等等; 其次是许多日常需要的小工具,包括系统管理员需要的脚本任务等等; 另外就是把其他语言开发的程序再包装起来,方便使用。
最后说说Python的缺点: 任何编程语言都有缺点,Python也不例外。优点说过了,那Python有哪些缺点呢?
第一个缺点就是运行速度慢,和C程序相比非常慢,因为Python是解释型语言,你的代码在执行时会一行一行地翻译成CPU能理解的机器码,这个翻译过程非常耗时,所以很慢。而C程序是运行前直接编译成CPU能执行的机器码,所以非常快。
第二个缺点就是代码不能加密。如果要发布你的Python程序,实际上就是发布源代码,这一点跟C语言不同,C语言不用发布源代码,只需要把编译后的机器 码(也就是你在Windows上常见的xxx.exe文件)发布出去。要从机器码反推出C代码是不可能的,所以,凡是编译型的语言,都没有这个问题,而解 释型的语言,则必须把源码发布出去。
2. Python 安装
因为Python是跨平台的,它可以运行在Windows、Mac和各种Linux/Unix系统上。在Windows上写Python程序,放到Linux上也是能够运行的。
要开始学习Python编程,首先就得把Python安装到你的电脑里。安装后,你会得到Python解释器(就是负责运行Python程序的),一个命令行交互环境,还有一个简单的集成开发环境。
2.1 Python2.x 和 Python3.x 的区别
目前,Python有两个版本,一个是2.x版,一个是3.x版,这两个版本是不兼容的,因为现在Python正在朝着3.x版本进化,在进化过程中,大量的针对2.x版本的代码要修改后才能运行,所以,目前有许多第三方库还暂时无法在3.x上使用。
从我自己的角度出发,学习Python2还是Python3是要看自己的需求,你要看看你所需要的库现在是否支持Python3[2]。但是我现在也是以一个初学者的身份来学习Python,并不确定在什么时候它能够派上用场,所以我觉得我可以从Python2版本开始入手学习,现在比较稳定的Python2的版本是Python 2.7.x。下面我就在我的电脑上安装Python2了。
以后,我在文中所指的Python都是指Python2版本。
2.2 Linux平台Python安装
通常当我们使用基于linux的ubuntu操作系统时,Ubuntu系统已经将Python作为一个内置的工具安装好了。除此之外,我们也可以通过Ubuntu系统自带的apt包管理器来安装Python,命令如下所示:
$ sudo apt-get install python
安装完成之后,我们可以通过以下命令来查看所安装的Python的版本
$ python --version
得到的结果为

然后在命令行窗口中输入“python”,如果出现下面的python交互界面,则说明python已经安装好了。

2.3 Python解释器
Python代码文件的后缀名是“.py”。如果我们想运行一个用python编写的“.py”文件,我们就需要一个Python的解释器,这是因为Python是一个解释型的语言。
Python的解释器有许多种,例如CPython、IPython、PyPy、JPython和IronPython,默认采用的解释器是CPython。
3. 第一个Python程序
第一个Python程序,依照惯例我们也来一个输出“Hello World!”的程序。下面这个程序是在Linux中的python交互环境中输入的代码。
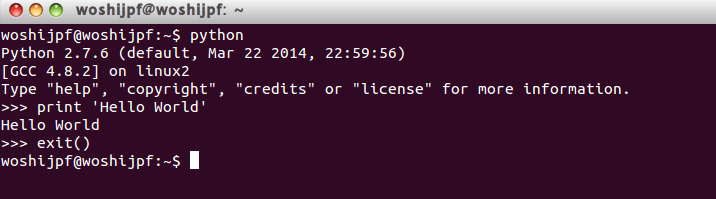
下面,我们就对这段简短的代码进行一个简要分析。
3.1 进入Python交互环境
在Linux系统环境下,通过在命令行窗口中输入“python”进入python交互环境。
3.2 退出Python交互环境
在交互环境中输入“exit()”退出Python交互环境。
3.3 使用文本编辑器编写
前面我们所介绍的是在python交互环境中写程序,但是这种方法编写的程序不能保存,而且每写一句就要被解释器解释执行一遍。因此,在实际的开发中,我们都是将程序编写成一个文件(例如python程序就是被编写为以“.py”为后缀的文件),这样程序就可以反复被调用执行了。所以,在一开始我们可以使用gedit或者vim作为编辑器编写我们的python程序。当你熟悉了python之后并且需要用python进行实际开发时,你可以尝试使用一些IDE集成开发环境,这回大大提高你的工作效率,在这里我推荐使用PyCharm。
3.4 运行python文件
在命令行运行python文件,首先,你需要将当前工作目录切换到你所要执行的python程序文件的目录下,然后执行下面的命令:
$ python pythonfilename.py
如果你希望能够向windows系统中的”.exe”文件一样,能够一双击就能自动运行,这时就需要我们对python文件添加一行代码,来指出解释运行该文件所需的应用程序。
#!/usr/bin/env python
是不是觉得很似曾相识,这个和我们以前写shell脚本程序一样,脚本语言的第一行,目的就是指出你想要你的这个文件中的代码用什么可执行程序去运行它。
在文件中添加完上面这行代码之后,下面一步还需要将文件通过”chmod”命令将文件变成可执行文件。
$ chmod 777 pythonfilename.py
然后,你就可以在命令行中像运行脚本程序一样运行pythonfilename.py文件了。
4. 输入输出
4.1 输出
python中输出功能是通过关键字“print”实现的。 ####输出字符串 用print加上想要输出的字符串,就能够实现向屏幕输出字符串了,其中我们想要输出的字符串需要包含在“”或者‘’之间,例如:
print 'Hello World!'
print语句后面也可以跟上多个字符串,字符串之间通过“,”来分隔,例如:
print 'How','are','you?'
最后的输出结果是:
How are you?
当print后面接上多个字符串时,遇到逗号它会自动输出一个空格。
####输出整数和浮点数 如果你想向屏幕上输出整数或者浮点数,那么很简单,你只需要在print后面直接加上你想输出的整数或者浮点数。
print 100
print 100+200
print 1.2345
运行得到的结果是:
100 300 1.234
4.2 输入
Python中提供了一个函数叫做“raw_input()”来实现输入功能,并将用户输入的值保存到变量中。例如:
name = raw_input()
Peter
下面我们就可以通过print来测试变量name中是否保存了我们输入的字符串“Peter”。
print name
得到的输出结果是
Peter
raw_input()函数还可以带上一个可选的参数,这个参数的作用就是提示用户输入,例如:
name = raw_input('Please input your name\n')
print 'name is',name
当我们输入“Peter”之后,得到的输出结果是
name is Peter
但是,如果我们想从外部读取一个整数时,我们该怎么办呢? raw_input()读取的内容永远以字符串的形式返回,但是我们可以在raw_input()前面加上强制转换int()时,我们就能够将读取到的字符串形式的整数转换成整数,例如:
>>> data1 = raw_input()
40
>>> data1
'40'
>>> data2 = int(data1)
>>> data2
40
>>> data3 = int(raw_input())
40
>>> data3
40
5. Python基础
每一种计算机编程语言都有自己的一套语法,Python也不例外,但和其他高级语言例如C,Java的语法也大同小异,下面就通过一个小例子来介绍下Python的基本语法。
#print absolute value of an integer
a = 100
if a >= 0:
print a
else:
print -a
-
Python中的注释符是“#”。
-
Python中每行语句后面不用加“;”最为结束符。
-
当语句以冒号”:”结尾时,缩进的语句块被视为是代码块。
-
Python是对大小写敏感的。
5.1 数据类型和变量
整数
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样,例如: 1,100,-8080,0,等等。
浮点数
浮点数就是小数,它可以采用数学中小数的写法,例如: 1.23,0.0001,-3.14等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
字符串
Python中的字符串指的是符号’‘或者“”括起来的任意文本,例如“abc”,’123’等等。但是如果字符串的文本中包含了单引号,那么文本可以采用”“括起来,例如”I’m OK“。如果字符串的文本包含了双引号,那么文本可以采用’‘括起来,例如’I”m OK’。假如,在字符串文本中包括了单引号’和双引号”,那么可以采用转义字符 \ 来标识,例如:
print 'I\'m \"OK'
输出的结果是:
I’m “OK
如果字符串里面需要很多字符需要转义,就需要加很多\,为了简化,Python还允许用r’‘表示’‘内部的字符串默认不转义,可以自己试试:
print '\\\t\\'
输出的结果为:
\ \
但是如果换成下面的形式,输出结果则又不同了。
print r'\\\t\\'
输出的结果为:
\\\t\
布尔值
一个布尔值只有True和False两种值,要么是True,要么是False(请注意大小写)。并且布尔值可以通过计算得到,例如:
>>>True
True
>>>False
False
>>>3 > 2
True
>>>2 > 3
False
布尔值可以用逻辑运算符and、or和not运算。
>>> True and False
False
>>> True or False
True
>>> not False
True
空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
变量
变量在程序中用一个变量名表示,变量名必须是大小写英文、数字和下划线”_“的组合,并且不能用数字作为开头,例如:
a = 7
变量a是一个整数。
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 #此时变量a是一个整数
print a
a = 'Hello' #此时变量a是一个字符串
print a
这种变量本身类型不固定的语言称为动态语言,与之相反的就是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下:
int a = 123; //变量a是整数类型的变量
a = "Hello"; //错误:不能把字符串赋值给整型类型的变量
常量
常量,顾名思义就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中通常采用全部大写的变量来表示常量,例如:
PI = 3.1415926
5.2 字符串和编码
字符串是一种数据类型,但是在字符串保存过程中还存在这一个字符编码的问题。下面就介绍下现在常用的三种通用字符编码。
- ASCII编码
- Unicode编码
- UTF-8编码
ASCII编码
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
Unicode编码
但是如果要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
UTF8编码
新的问题又出现了: 如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
下面我们就具体举例对三种编码进行一个对比分析。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 0100000 | 01000001 |
| 中 | 无 | 01001110 001011 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
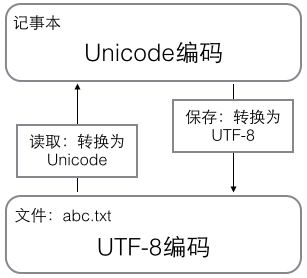
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
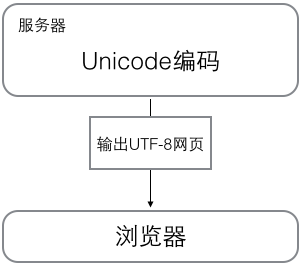
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
Python中的字符串
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串’ABC’在Python内部都是ASCII编码的。Python提供了ord()和chr()函数,可以把字母和对应的数字相互转换:
>>> ord('A')
65
>>> chr(97)
a
Python在后来添加了对Unicode的支持,以Unicode表示的字符串以u’…‘来表示:
>>> print u'中国'
中国
>>>u'中'
u'\u4e2d'
因此,写u’中‘和写u’\u4e2d’是一样的,在’\u’后面是16进制表示的Unicode编码值。
字符串’xxx’虽然是ASCII编码,但也可以看成是UTF-8编码,而u’xxx’则只能是Unicode编码。
Unicode字符串u’xxx’转换为UTF-8编码的’xxx’用encode(‘utf-8’)方法
>>> u'ABC'.encode('utf-8')
'ABC'
>>> u'中国'.encode('utf-8')
'\xe4\xb8\xad\xe5\x9b\xbd'
英文字符转换后表示的UTF-8的值和Unicode值相等(但占用的存储空间不同),而中文字符转换后1个Unicode字符将变为3个UTF-8字符,你看到的\xe4就是其中一个字节,因为它的值是228,没有对应的字母可以显示,所以以十六进制显示字节的数值。len()函数可以返回字符串的长度:
>>> len(u'ABC') #占用6个字节的存储空间
3
>>> len('ABC') #占用3个字节的存储空间
3
>>> len(u'中国') #占用4个字节的存储空间
2
>>> len('\xe4\xb8\xad\xe5\x9b\xbd') #占用6个字节的存储空间
6
UTF-8编码表示的字符串’xxx’转换为Unicode字符串u’xxx’用decode(‘utf-8’)方法
>>> 'ABC'.decode('utf-8')
u'ABC'
>>> '中国'.decode('utf-8')
u'\u4e2d\u56fd'
>>> '\xe4\xb8\xad\xe5\x9b\xbd'.decode('utf-8')
u'\u4e2d\u56fd'
>>> print '\xe4\xb8\xad\xe5\x9b\xbd'.decode('utf-8')
中国
python脚本文件中一定要在代码前面指定编码格式
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
所以,在使用Python读取文件时,一定要注意你所读取文件的编码格式问题。
5.3 格式化
在Python中,格式化的方法和C语言一样都是采用百分号%实现的,例如:
>>> "Hello,%s" % 'world'
'Hello,world'
>>> 'Hi,%s,you have $%d' % ('Peter',10000)
'Hi,Peter,you have $10000'
%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有以下几种:
- %s 字符串
- %d 整数
- %f 浮点数
- %x 十六进制数
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d - %02d' % (1,2)
' 1 - 02'
>>> '%.2f' % (3.1415916)
'3.14'
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age = %s , Gender = %s' % (23,'Male')
'Age = 23 , Gender = Male'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%
>>> 'growth rate: %d %%' % (20)
'growth rate: 20 %'
5.4 使用list和tuple
list
Python内置的一种数据类型是列表: list。list是一种有序的集合,可以随时添加和删除其中的元素。它的特点与Java中的List容器类似。
例如,列出一个班级上的同学的姓名,就可以用一个list来表示:
>>> classmates = ['Bob','Michael','Tracy']
['Bob', 'Michael', 'Tracy']
此时,变量classmates就是一个list。而且,我们可以用函数len()来求得list的长度
>>> len(classmates)
3
采用索引的方式来访问list中的每个元素,记得list的索引和数组一样都是从0开始的。
>>> classmates[0]
'Bob'
在list中还可以通过索引-1直接访问到list中最后一个元素,
>>> classmates[-1]
'Tracy'
以此类推,我们可以使用[-2],[-3]的方式以此访问到list中倒数第2和倒数第3个元素。
list是一个有序列表,还拥有自己的一些成员函数,如下所示:
| 函数 | 功能 |
|---|---|
| append() | 向list的末尾添加新的元素 |
| pop() | 删除list末尾的元素 |
| insert() | 把元素插入到list中的指定位置 |
append函数
函数原型: append(待插入数据元素) 函数功能: 将数据元素参数插入到list的末尾。 例子:
>>> classmates.append('Adam')
>>> classmates
['Bob', 'Michael', 'Tracy', 'Adam']
insert函数
函数原型: insert(待插入位置索引,待插入数据元素) 函数功能: 在索引指定位置插入待插入的数据元素 例子:
>>> classmates.insert(1,'Tom')
>>> classmates
['Bob', 'Tom', 'Michael', 'Tracy', 'Adam']
pop函数
函数原型: pop(待删除元素的索引),pop() 函数功能: 如果括号内有参数,则删除索引指定位置数据元素,否则就删除list中的最后一个元素。 例子:
>>> classmates.pop(1)
'Tom'
>>> classmates
['Bob', 'Michael', 'Tracy', 'Adam']
>>> classmates.pop()
'Adam'
>>> classmates
['Bob', 'Michael', 'Tracy']
在list中的数据元素类型可以各不相同,例如:
>>> l = ['Hello',123,0.9999]
>>> l
['Hello', 123, 0.9999]
如果list中一个元素也没有,那么这就是一个空的list。
>>> l = []
>>> l
[]
>>> len(l)
0
tuple
另一种有序列表叫元组: tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,同样是列出同学的名字,tuple的表示方法是:
>>> classmates_tuple = ('Bob','Michael','Tracy')
>>> classmates_tuple
('Bob', 'Michael', 'Tracy')
在这里特别要注意一点,list中的数据元素是用方括号[]括起来的,而tuple中的数据元素则是用小括号()括起来的。
现在tuple类型变量classmates_tuple,它没有insert,pop和append的方法,但是可以通过索引的方式来访问tuple中的数据元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
当你想定义一个空的tuple变量时,你可以定义成下面这样:
>>> t = ()
>>> t
()
但是如果你想定义只有一个元素的tuple时,你会这样定义吗?
>>> t = (1)
>>> t
1
但是这种方式定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有一个t元素的tuple定义时,必须在后面加上一个逗号“,”来消除歧义:
>>> t = (1,)
>>> t
(1,)
最后来看一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
这个tuple定义的时候有3个元素,分别是’a’,’b’和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?
别急,我们先看看定义的时候tuple包含的3个元素:
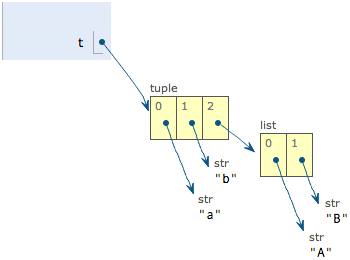
当我们把list的元素’A’和’B’修改为’X’和’Y’后,tuple变为:
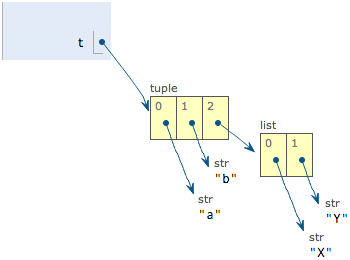
表面上看是tuple发生了变化,但是仔细研究其实是tuple中的list元素发生了变化。tuple中一开始的指向的list并没有改变成别的list,所以tuple中的“不变”指的是tuple中的每个元素的指向永远不变。即指向’a’,就不能改成指向’b’,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
python中的id()方法返回的值是对象的内存地址,所以我们可以借助id()方法检验以下修改了tuple中的list中的元素,tuple中的list元素对象是否发生了变化:
>>> t = ('a','b',['A','B'])
>>> t
('a', 'b', ['A', 'B'])
>>> id(t[2])
139769942204000
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
>>> id(t[2])
139769942204000
最后,从结果分析来看,tuple中第三个list对象的确没有变,修改前后它所指向的内存地址都是相同的。
5.5 条件判断
Python中判断语句的格式为:
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>
5.6 循环语句
Python中有两种循环语句格式
- for…in…
- while
一种是for x in y 格式的循环语句,这种循环就是把y中的每个元素代入到x中,然后执行缩进块中的语句,通常变量y都是list和tuple格式,例如:
names = ['Michale','Jack','Bob','Woshijpfgg'];
for name in names:
print name
执行上面这段代码后,输出的结果为
Michale Jack Bob Woshijpfgg
另外一种循环结构是while循环,当满足while后的条件时,就不断执行循环的代码块,如果不满足条件时,就跳出循环。例如,我们想计算100以内所有奇数的和,我们可以这样计算:
sum = 0
n = 1
while n <= 100:
sum = sum + n
n = n + 2
print sum
5.7 dict
Python中内置了dict,也称为字典,在其他语言中也叫做map,它是用来存储键值(key-value),它具有极快的查找速度。 在Python中定义一个dict变量的方法,如下所示:
>>> d = {'Michael':95,'Bob':100,'Tracy':60}
>>> d
{'Bob': 100, 'Michael': 95, 'Tracy': 60}
>>> d['Michael']
95
从上面的dict类型变量的定义可以看出,dict类型变量在定义时有花括号{}括起来,dict中的每个元素有一个键-值(key-value)对组成,在冒号”:”前面的字符串时key,而在冒号”:”后面的整数则是value。
并且要保证一个key只能对应一个value,如果重复对一个key放入不同的value,后面的值会把前面的值覆盖了。
判断一个key是否在dict中,我们可以有两种方法来解决。 第一种就是使用in方法来判断一个key是否在dict中,例如
>>> 'Thomas' in d
False
>>> 'Bob' in d
True
第二种方法就是使用dict提供的get方法,如果key不存在,则会返回一个None(空值),否则就会返回key对应的value值,例如:
>>> d.get('Thomas')
>>> d.get('Bob')
100
如果我们想从字典中删除一个key-value对,我们可以采用dict提供的pop(key)的方法进行删除,例如:
>>> d.pop('Tracy')
60
>>> d
{'Bob': 100, 'Michael': 95}
和list相比,dict有以下几个特点:
- 查找和插入的时间极快,不会随着key的增加而增加。
- 需要占用大量的内存,内存浪费多。
在使用dict时,一定要牢记一点 dict中的key对象一定是不可变对象
为什么要求dict中的key是不可变对象呢? 这是因为dict是根据计算key来得到对应value在内存中的存储位置的,所以如果每次key计算出来的结果不相同,那dict内部就完全混乱了,而这个key计算value位置的算法就是我们熟悉的哈希算法(Hash algorithm)
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
>>> key = [1,2,3]
>>> d[key] = 'a list'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> key = 'Thomas'
>>> d[key] = 30
>>> d
{'Bob': 100, 'Michael': 95, 'Thomas': 30}
5.8 set
set与dict类似,它是一组key的集合,但它不存储value。并且在set中,key时不能重复的,他要符合集合中的唯一性。
在创建set时,需要提供一个list作为输入集合,例如:
>>> s = set([1,2,3])
>>> s
set([1, 2, 3])
注意,传入的参数[1, 2, 3]是一个list,而显示的set([1, 2, 3])只是告诉你这个set内部有1,2,3这3个元素,显示的[]不表示这是一个list。
可以通过add(key)的方法将元素添加到set中,但是重复添加不会有效果,例如:
>>> s.add(4)
>>> s
set([1, 2, 3, 4])
>>> s.add(4)
>>> s
set([1, 2, 3, 4])
也可以通过remove(key)的方法将元素从set中删除,例如:
>>> s.remove(4)
>>> s
set([1, 2, 3])
set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
set([2, 3])
>>> s1 | s2
set([1, 2, 3, 4])
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。 如果将可变对象list放入set,则会报错,如下所示:
>>> key = [1,2,3]
>>> s.add(key)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
5.9 不可变对象
上面我们提到list时可变对象,而字符串是不可变对象。
对于可变对象,比如list,对其进行操作,它内部的内容是会变化的,例如:
>>> l = [3,1,2]
>>> l
[3, 1, 2]
>>> l.sort()
>>> l
[1, 2, 3]
而对于不可变对象字符串,我们执行以下操作:
>>> a = "abc"
>>> a
'abc'
>>> a.replace('a','A')
'Abc'
>>> a
'abc'
有没有觉得很奇怪,我们都对字符串s执行了replace()操作,但是最后我们输出的字符串变量s中的内容却仍然是‘ABC’。 我们可以将代码改成下面这样更便于理解:
>>> a = "abc"
>>> a
'ABC'
>>> b = a.replace('a','A')
>>> b
'Abc'
>>> a
'abc'
要始终牢记,a 是变量,而‘abc’才是真正的字符串对象。

当我们调用a.replace(‘a’, ‘A’)时,实际上调用方法replace是作用在字符串对象’abc’上的,而这个方法虽然名字叫replace,但却没有改变字符串’abc’的内容。相反,replace方法创建了一个新字符串’Abc’并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串’abc’,但变量b却指向新字符串’Abc’了:
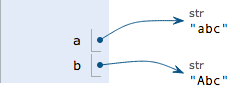
所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
##参考链接
Subscribe via RSS