《Linux 内核分析》完成一个简单的时间片轮转多道程序内核代码
by FlyFlyPeng
1. 概要
上周我在网易云课堂上学习了孟宁老师的《Linux 内核分析》第二周的课程内容:操作系统是如何工作的?课程的重点内容就是介绍了函数调用堆栈的过程、Linux 中内联汇编的使用方法,以及一个基于 Linux 3.9.4 内核自己实现的时间片轮转多道程序内核。
本文就主要对最后一个重点内容:一个简单的时间片轮转多道程序内核代码 进行一个分析。
2. 实验环境搭建
首先,当然是要搭建好实验的环境,实验中使用到的主要是在 qemu 模拟器中运行我们自己编写的非常简单的内核。实验环境的具体的搭建过程在孟宁老师的 github 中的 mykernel 项目中的 README 文档中有详细的说明。
我是在自己本地电脑上的 Ubuntu 14.04 64位版本电脑上进行实验的。
3. 原理分析
为了精简内核初始化启动的过程,上一步中我们在现有的 Linux 3.9.4 的源码基础上,打上了孟宁老师为我们准备好的内核补丁,这样我们的内核启动后就会从打上补丁后 Linux 源码目录下的 kernel/mymain.c 文件中__init my_start_kernel() 函数开始执行,关于如何实现上述的过程,我们不做深究,现在只需知道打完补丁之后,我们就可以从这个函数开始执行我们自己编写的内核代码了。
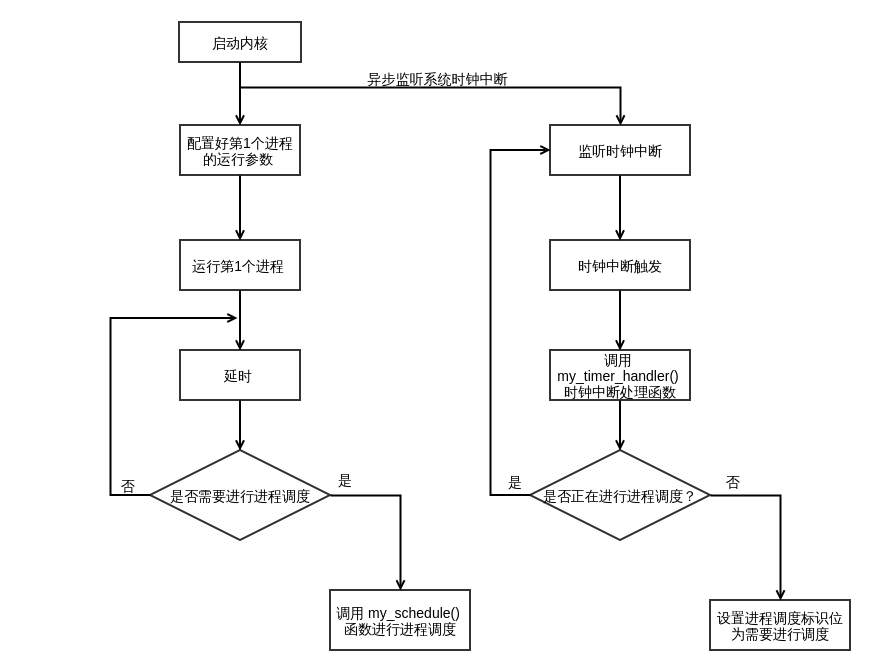
首先,先直观地给出整个时间片轮转多道程序内核代码的执行过程的一个流程示意图:
3.1 进程控制块(PCB)
如果学习过操作系统的理论原理,那么你一定不会对进程控制块这个名词感到陌生。
进程控制块是一个数据结构,它保存了描述一个进程所需的各种信息,例如进程的编号(pid),进程的当前状态(status),进程的内核栈(kernel stack),程序计数器(PC)等等。
在本实验中,我们就定义了如下所示的进程控制块结构:
// 代码中文件 mypcb.h 中
#define MAX_TASK_NUM 4
#define KERNEL_STACK_SIZE 4*1024
// 定义一个进程中主线程执行时,CPU 中 eip 和 esp 寄存器中的值
struct Thread
{
unsigned long ip;
unsigned long sp;
};
// 进程控制块定义
typedef struct PCB
{
int pid; // 进程号
volatile long state; // 表示当前进程的状态, -1: 不可运行,0: 运行中,>0: 停止
char stack[KERNEL_STACK_SIZE]; // 内核堆栈空间
// 进程执行时的 CPU 中关键寄存器的状态
struct Thread thread;
// 进程中主程序的入口地址
unsigned long task_entry;
struct PCB *next; // 指向下一个进程控制块
} tPCB;
为了方便管理,我们在我们的内核里将进程块按照循环链表的形式进行管理。
上面的代码中的注释已经非常清楚了,下面还要补充一点关于 PCB 中struct Thread thread 字段的说明。结构体 Thread 中就定义两个数据成员:
- ip: 表示的含义是进程下一条执行指令的地址
- sp: 表示的含义是使用进程中内核栈中的栈顶指针,初始时指向栈底 (KERNEL_STACK_SIZE-1)。
3.2 中断
中断机制是现代计算机中不可或缺的一种运行机制,它允许你暂停当前正在执行的程序流,转而去执行另外一个可能是非常紧急或重要的处理程序,然后执行完了之后,又返回到原来的程序流接着往下执行,这种机制增强了计算机运行程序的灵活性。
正如我们现在能在计算机中同时(这里的同时指的是一个很短暂的时间范围,例如10ms)运行多个进程,这是得益于中断这种机制,它让我们的计算机可以在程序之间在短时间内可以完成快速地切换。
有关中断的初始化等一系列调用中断处理函数前的工作,已经由我们打的内核补丁和 Linux 内核帮我们完成了,所以我们所需要做的就是编写中断处理函数,在中断处理函数中处理我们进程时间片轮转的进程调用工作。
下面我们就来看看中断处理函数的实现:
// 代码在文件 myinterrupt.c 文件中
extern volatile int my_need_sched;
volatile int time_count = 0;
/*
* Called by timer interrupt.
*/
void my_timer_handler(void)
{
if (time_count % 1000 == 0 && my_need_sched != 1) // 每个 1000 次时间中断并且没有进行调度,则执行一次打印输出
{
printk(KERN_NOTICE ">>>my_timer_handler here<<<\n");
my_need_sched = 1; //进行调度
}
time_count++;
}
由于系统的时钟中断是由 CPU 的运行主频决定的,假设我们用 qemu 模拟出来的 CPU 主频为 1GHZ,那么它表示 CPU 的一个始终周期是 1 ns,为了使得我们能够看得出调度的效果,我们程序里就使用了一个计算值,每隔 1000 个时钟周期来处理一次进程调度。
并且,如果进行调度的标志位 my_need_sched 为0,则在中断处理程序中将其设置为 1,表示需要进行一次进程调度了。如果进行调度的标志位 my_need_sched 为 1,则表示已经正在进行调度了。
3.3 创建多个进程
我们的实验目的就是为了实现多个进程之间轮转,那么我们当然需要创建好一组进程啦。
下面我们就直接上代码了:
// 代码位于 mymain.c 文件中
tPCB task[MAX_TASK_NUM]; // 创建包含所有进程的进程数组
tPCB *my_current_task = NULL; // my_current_task 指针指向当前正在运行的进程的进程控制块
volatile int my_need_sched = 0; // 是否需要进行调度的标志
void my_process(void);
// 这个 my_start_kernel 是经过打过补丁之后,新的内核的开始执行的入口函数
void __init my_start_kernel(void)
{
int pid = 0;
int i;
// 初始化 0 号进程
task[pid].pid = 0;
task[pid].state = 0; // 0 表示当前进程正在执行
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process; // 将第 0 号进程的主函数入口地址设置为 my_process
// my_process 是定义在本文件中的一个函数
task[pid].thread.sp = (unsigned long) & (task[pid].stack[KERNEL_STACK_SIZE - 1]); // 将进程中的栈指针 sp 指向进程所使用栈的栈顶
task[pid].next = &task[pid]; // 在还没有初始化更多进程之前,它所指向的下一个进程块还是它自己
// fork 出更多的进程
for (i = 1; i < MAX_TASK_NUM; i++)
{
// 首先使用 0 号进程对应的进程块中的内容来初始化其他新创建的进程
memcpy(&task[i], &task[0], sizeof(tPCB));
task[i].pid = i;
task[i].state = -1;
task[i].thread.sp = (unsigned long) & (task[i].stack[KERNEL_STACK_SIZE - 1]);
task[i].next = task[i - 1].next;
task[i - 1].next = &task[i];
}
......
}
首先,在这个文件中我们创建一个进程控制块的数组 task,它里面保存了 MAX_TASK_NUM(值等于4)个进程的控制块。
接下来第二步就是对我们进程控制块中的每个数据成员进行赋值初始化了。
其中以下这句:
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process
表示的是将进程下一条执行的指令地址,指向函数 my_process() 的地址,同时设置这个函数的地址为进程执行的入口地址。
而下面这句:
task[pid].next = &task[pid];
这里我们对进程控制块的管理方式,使用的是循环链表的结构,所以初始化第一个进程的时候,进程控制块中 next 指针就指向了它自己。
初始化完成第一个进程之后,我们用同样的方式去初始化进程中的其他三个进程,并将新初始化完成的进程控制块添加到循环链表中。
3.4 启动运行第 0 号进程
完成了进程初始化之后,我们就可以启动运行我们内核的第 0 号进程了(这个进程就是内核中第一个运行的进程)。而启动运行第 0 号进程,整个启动过程主要是由 Linux 中的内联汇编完成,具体的代码如下所示:
// 代码位于 mymain.c 文件中
// 准备启动第 0 号进程
pid = 0;
my_current_task = &task[0];
asm volatile (
"movl %1,%%ebp\n\t" // 应该将 "pushl %1\n\t" 替换成这句话,并放在现在这个位置
"movl %1,%%esp\n\t" // 将 task[pid].thread.sp 的值存放到 esp 寄存器中
// "pushl %1\n\t" // 这句话得删除了,添加第一句汇编代码
"pushl %0\n\t" // 将进程 0 主函数入口地址压入堆栈
"ret\n\t" // 弹出进程 0 的 ip 值到 eip 寄存器中
"popl %%ebp\n\t" //将进程 0 对应的栈的栈底弹出到 ebp 寄存器中
: // 没有输出
: "c"(task[pid].thread.ip), "d"(task[pid].thread.sp)
);
其中,asm volatile(); 括号中的就是内联汇编,如果你要读懂内联汇编的代码,你可能还需要一点汇编的基础知识,有关 Linux 中的 AT&T 汇编,你可以参考这篇文章:Linux 中 x86 的内联汇编。
这里我觉得需要对老师提供的代码做一个小的修正:
pushl %1\n\t //将这句话删除了
movl %1,%%ebp\n\t //在内联汇编的第一行中加上这句
因为,当初始化一个进程的栈时,首先第一步要做的就是指向栈底和栈顶的寄存器 ebp 和 esp,而 **push %1\n\t ** 这句代码并没有很好的体现这种意思。并且经过测试,这样的修改是对的,进程键的轮转也正常地实现了。
有关代码的说明,都在上面的代码的注释中,但是这里还着说明一下下面这两行代码的含义:
pushl %0\n\t // 讲进程 0 主函数入口地址压入堆栈
ret\n\t // 弹出进程 0 的 ip 值到 eip 寄存器中
其中 pushl 语句的功能就是将进程初始时执行的第一条指令的地址(也就是函数 my_process 的地址)压入堆栈中,接着使用了 ret 指令将当前栈顶保存着的刚压入栈顶的 my_process 函数的首地址保存到 eip 寄存器中。这里补充一下 eip 寄存器的作用,它保存的是计算机中下一条执行指令的地址,也就是说,接下来程序就会从汇编指令 ret 跳转到函数 my_process() 去执行。
3.5 进入进程的主函数 my_process() 运行
当上一步中内联汇编程序中的 ret 指令执行完毕后,第 0 号进程就会跳转到 my_process() 函数中继续执行。其实这里的 my_process() 函数有点类似于我们平时最常见的 main 函数,它相当于我们自定进程的主函数。
虽然我们最开始接触编程就是从 main 函数开始的,知道main 函数是整个程序执行的入口,但是我们可能对 main 函数是如何由操作系统进行加载运行的,其实事实上 main 函数并不是我们运行程序时那个进程的第一条指令的地址,进程需要初始化建立好 main 函数的运行环境,然后才跳转到 main 函数中开始执行 main 函数中的代码。
Ok,有点扯远了,现在我们就来看看 my_process() 函数的源码:
// 自定义进程所对应的主函数,类似于我们 C 语言中的 main 函数
void my_process(void)
{
int i = 0;
while (1)
{
i++;
if (i % 10000000 == 0) // 每执行 10000000 次来进行一次主动的进程调度
{
printk(KERN_NOTICE "this is process %d -\n", my_current_task->pid);
// 如果需要进行调度
if (my_need_sched == 1)
{
my_need_sched = 0;
my_schedule();
}
printk(KERN_NOTICE "this is process %d +\n", my_current_task->pid);
}
}
return;
}
为了让我们的进程一直在运行,所以在 my_process() 中就包含了一个死循环,然后程序就在死循环中不停地在执行,并且在死循环中还添加一个判断语句,每执行 10000000 次循环,就判断是否需要进行进程调度,如果需要就跳转到 my_schedule() 函数(my_schedule() 函数在 my_interrupt.c 文件中实现)中进行进程的主动轮转调度。
3.6 进程调度 – my_schedule()
my_schedule() 函数的主要功能就是切换进程执行,而进程间切换主要需要完成的工作就是保存进程的上下文环境,换句话说,就是先保存上一个进程的执行时相关寄存器的状态(例如 ebp,esp,eip等寄存器中内容),以便进程切换回来时能够从上一次执行的位置继续往下执行。具体函数代码实现如下所示:
// 代码实现在 myinterrupt.c 文件中
void my_schedule(void)
{
tPCB *next; // 下一个需要调度的进程
tPCB *prev; // 调度前执行的进程
if (my_current_task == NULL || my_current_task->next == NULL)
{
return ;
}
printk(KERN_NOTICE ">>> my_schedule <<<\n");
next = my_current_task->next;
prev = my_current_task;
if (next->state == 0)
{
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n", prev->pid, next->pid);
/* switch to next process */
asm volatile (
"pushl %%ebp\n\t" // 保存 prev 进程的栈底指针地址,并将其压入到 prev 栈中
"movl %%esp, %0\n\t" // 将 prev 进程中 栈顶指针 esp 保存到 prev 进程控制块中 thread.sp 数据成员中
"movl %2, %%esp\n\t" // 将 next 指向进程中的栈底指针保存到 esp 中
"movl $1f,%1\n\t" // 将 prev 指向进程下一条要执行的指令保存到进程控制块中
"pushl %3\n\t" // 将 next 指向进程的下一条指令入栈
"ret\n\t" // 将 next 进程需要执行的下一条指令弹出到 eip 寄存器中
"1: \t"
"popl %%ebp\n\t" // 弹出 next 进程栈订顶的值到 ebp 寄存器中
: "=m"(prev->thread.sp), "=m"(prev->thread.ip)
: "m"(next->thread.sp), "m"(next->thread.ip)
);
}
else {
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n", prev->pid, next->pid);
/* switch to new process */
asm volatile (
"pushl %%ebp\n\t" // 将 prev 进程中栈的栈底指针保存到 prev 栈中
"movl %%esp,%0\n\t" // 将 prev 进程中 栈顶指针 esp 保存到 prev 进程控制块中 thread.sp 数据成员中
"movl %2,%%ebp\n\t" // 将 next 进程的栈底地址送到 ebp 寄存器中
"movl %2,%%esp\n\t" // 将 next 进程的栈顶地址送到 esp 寄存器中
"movl $1f,%1\n\t" // 保存 prev 指向进程下一次执行时的指令地址,也就是标号为 1 处的地址
"pushl %3\n\t" // 将 next 进程的入口地址压入到栈中
"ret\n\t" // 将 next 进程的下一条执行的指令弹出,然后从刚弹出的指令地址开始执行
: "=m"(prev->thread.sp), "=m"(prev->thread.ip)
: "m"(next->thread.sp), "m"(next->thread.ip)
);
}
return;
}
下面我们就详细来分析下这个函数的实现:
-
step 1:首先函数中先定义了两个进程控制块的指针next 和 prev ,分别用来指向下一个轮转到的进程,以及轮转前执行的进程。
-
step 2:接下来,我们就得对分两种情况进行讨论了,第一种情况是进程链表中下一个轮转到的进程还从未运行过,第二种情况是下一个轮转到的集成已经在运行了。这两种情况的主要区别就在于第一种情况中在内联汇编代码中需要首先初始化进程中的栈,第二种情况中每个进程的栈都已经初始化好了,只需要简单地切换栈即可。
-
step 3: 有关两种情况所执行的内联汇编代码的含义,我都在上面的代码中给出了详细的注释。
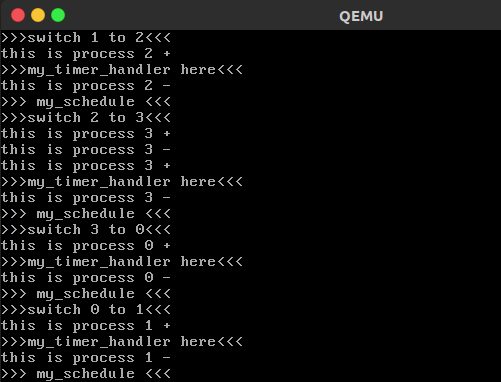
4. 实验结果
最后,我们将上面的代码重新 “make” 编译之后,然后使用以下命令启动 qemu 来运行我们的内核程序:
$ qemu -kernel arch/x86/boot/bzImage
实验结果截图如下所示:
5. 总结
写到最后,我觉得对于这样一个简单的时间片轮转多道程序内核代码,我也是花了好几天才真正的理解清楚,而且当我在写这篇文章的时候,会发现原来自己感觉想清楚的地方事实上并没有完全地弄懂,于是又一遍一遍地看代码,画个栈的草图来模拟整个执行的过程,然后才慢慢地理解地更加深一层。
如果大家对这个过程还不是特别清楚,我强烈地推荐大家多画草图,把每个进程中栈的变化给弄清楚,如果光靠脑子想想是很难把这些抽象的东西给理得很顺。
Subscribe via RSS